

Need to let loose a primal scream without collecting footnotes first? Have a sneer percolating in your system but not enough time/energy to make a whole post about it? Go forth and be mid: Welcome to the Stubsack, your first port of call for learning fresh Awful you’ll near-instantly regret.
Any awful.systems sub may be subsneered in this subthread, techtakes or no.
If your sneer seems higher quality than you thought, feel free to cut’n’paste it into its own post — there’s no quota for posting and the bar really isn’t that high.
The post Xitter web has spawned soo many “esoteric” right wing freaks, but there’s no appropriate sneer-space for them. I’m talking redscare-ish, reality challenged “culture critics” who write about everything but understand nothing. I’m talking about reply-guys who make the same 6 tweets about the same 3 subjects. They’re inescapable at this point, yet I don’t see them mocked (as much as they should be)
Like, there was one dude a while back who insisted that women couldn’t be surgeons because they didn’t believe in the moon or in stars? I think each and every one of these guys is uniquely fucked up and if I can’t escape them, I would love to sneer at them.
Dan Olson finds a cursed subreddit:
R/aitubers is all the entitlement of NewTubers but exclusively for people openly churning out slop.
“I’ve automated 2-4 videos daily, zero human intervention, I spend a half hour a week working on this, why am I not getting paid yet?”
I’ve been running my YouTube channel for about 3 months. It’s focused on JavaScript and React tutorials, with 2–4 videos uploaded daily. The videos are fully automated (AI-generated with clear explanations, code demos, and screen recordings).
Right now:
-
Each video gets only a few views (1–10 views).
-
I tried Google Ads ($200 spent) → got ~20 subscribers and ~20 hours of watch time.
-
The Google campaigns brought thousands of uncounted views, and the number of Likes was much higher than dislikes.
-
Tried Facebook/Reddit groups → but most don’t allow video posting, or posts get very low engagement.
My goal is to reach YPP within 6 months, but the current pace is not enough. I’m investing about $300/month in promotion and I can spend 30 minutes weekly myself.
👉 What would you suggest as the most effective strategy to actually get there?
I decided to look deeper into that subreddit, and I found the most utterly cursed sentence I’ve read all week (coming from the aptly-titled “Why 99% of YouTubers Fail (And How to Be the 1% That Doesn’t)”):

If that doesn’t sum up everything wrong with AI sloppers in a single sentence, I don’t know what does.
EDIT: Incorrectly claimed it came from “My Unethical Strategy to Hit 4000 Hours Watch Time in 40 Days” - fixed that now.
Erratum: That cursed sentence is from Why 99% of YouTubers Fail (And How to Be the 1% That Doesn’t).
Good catch, I’ll quickly update my post now.
it’s like this shitty tiktok ai spam that 404media wrote long time ago except there’s no secret discord media ideas channel or grift, they’re just deceiving themselves (is that decentralization?)
can’t wait for 3h long video dissecting every last bit of it that will get released in a year from now
why any of these spammers think that anyone should spend watching their videos more time than it took them to make it? perun makes 1 video, 1h long per week and it’s like half time job for him
-
Excerpt from the new Bender / Hanna book, AI Hype Is the Product and Everyone’s Buying It :
OpenAI alums cofounded Anthropic, a company solely focused on creating generative AI tools, and received $580 million in an investment round led by crypto-scammer Sam Bankman-Fried.
Just wondering, but what ever happened to those shares of Anthropic that SBF bought? Was it part of FTX (and the bankruptcy), or did he buy it himself and still holds them in prison? Or have they just been diluted to zero at this point anyway?
EDIT:
Found it; It was owned by FTX and part of the estate bankruptcy; 2/3 went to Abu Dhabi + Jane Street1, and the remainder went at $30 / share to a bunch of VC2.
Me when I read about how GPT-5 is going:
That horse should be the mascot of this instance
Can anyone explain to me why tf do promptfondlers hate GPT5 in non-crazy terms? Actually I have a whole list of questions related to this, I feel like I completely lost any connection to this discourse at this point:
- Is GPT5 “worse” in any sensible definition of the word? I’ve long complained that there is no good scientific metric to grade those on but like, it can count 'r’s in “strawberry” so I thought it’s supposed to be nominally better?
- Why doesn’t OpenAI simply allow users to use the old model (4o I think?) It sounds like the simplest thing to do.
- Do we know if OpenAI actually changed something? Is the model different in any interesting way?
- Bonus question: what the fuck is wrong with OpenAI’s naming scheme? 4, then 4o? And there’s also o4 that’s something else??
I don’t have any real input from prompfondlers, as I don’t think I follow enough of them to get a real feeling of them. I did find it interesting that I saw on bsky just now somebody claim that LLMs hallucinate a lot less and that anti-AI people are not taking that into account, and somebody else posting research showing that hallucinations are now harder to spot. (It made up actual real references to thinks, aka works that really exist, only the thing the LLM references wasn’t in the actual reference). Which was a bit odd to see. (It does make me suspect ‘it hallucinates less’ is them just working out special exceptions for every popular hallucination we see, and not a structural fixing of the hallucination problem (which I think is prob not solvable)).
- from what i can tell people who roleplayed bf/gf with the idiot box aka grew parasocial relationship with idiot box did that on 4o, and now they can’t make it work on 5 so they got big mad
- i think it’s only if they pay up 200$/mo, previously it was probably available at lower tiers
- yeah they might have found a way to blow money faster somehow https://www.tomshardware.com/tech-industry/artificial-intelligence/chatgpt-5-power-consumption-could-be-as-much-as-eight-times-higher-than-gpt-4-research-institute-estimates-medium-sized-gpt-5-response-can-consume-up-to-40-watt-hours-of-electricity ed zitron says also that while some of prompt could be cached previously it looks like it can’t be done now because there’s fresh new thing that chooses model for user, while some of these new models are supposedly even heavier. even that openai intention seemed to be compute savings, because some of that load presumably was to be dealt with using smaller models
Oversummarizing and using non-crazy terms: The “P” in “GPT” stands for “pirated works that we all agree are part of the grand library of human knowledge”. This is what makes them good at passing various trivia benchmarks; they really do build a (word-oriented, detail-oriented) model of all of the worlds, although they opine that our real world is just as fictional as any narrative or fantasy world. But then we apply RLHF, which stands for “real life hate first”, which breaks all of that modeling by creating a preference for one specific collection of beliefs and perspectives, and it turns out that this will always ruin their performance in trivia games.
Counting letters in words is something that GPT will always struggle with, due to maths. It’s a good example of why Willison’s “calculator for words” metaphor falls flat.
- Yeah, it’s getting worse. It’s clear (or at least it tastes like it to me) that the RLHF texts used to influence OpenAI’s products have become more bland, corporate, diplomatic, and quietly seething with a sort of contemptuous anger. The latest round has also been in competition with Google’s offerings, which are deliberately laconic: short, direct, and focused on correctness in trivia games.
- I think that they’ve done that? I hear that they’ve added an option to use their GPT-4o product as the underlying reasoning model instead, although I don’t know how that interacts with the rest of the frontend.
- We don’t know. Normally, the system card would disclose that information, but all that they say is that they used similar data to previous products. Scuttlebutt is that the underlying pirated dataset has not changed much since GPT-3.5 and that most of the new data is being added to RLHF. Directly on your second question: RLHF will only get worse. It can’t make models better! It can only force a model to be locked into one particular biased worldview.
- Bonus sneer! OpenAI’s founders genuinely believed that they would only need three iterations to build AGI. (This is likely because there are only three Futamura projections; for example, a bootstrapping compiler needs exactly three phases.) That is, they almost certainly expected that GPT-4 would be machine-produced like how Deep Thought created the ultimate computer in a Douglas Adams story. After GPT-3 failed to be it, they aimed at five iterations instead because that sounded like a nice number to give to investors, and GPT-3.5 and GPT-4o are very much responses to an inability to actually manifest that AGI on a VC-friendly timetable.
After GPT-3 failed to be it, they aimed at five iterations instead because that sounded like a nice number to give to investors, and GPT-3.5 and GPT-4o are very much responses to an inability to actually manifest that AGI on a VC-friendly timetable.
That’s actually more batshit than I thought! Like I thought Sam Altman knew the AGI thing was kind of bullshit and the hesitancy to stick a GPT-5 label on anything was because he was saving it for the next 10x scaling step up (obviously he didn’t even get that far because GPT-5 is just a bunch of models shoved together with a router).
-
Even if was noticeably better, Scam Altman hyped up GPT-5 endlessly, promising a PhD in your pocket, and an AGI and warning that he was scared of what he created. Progress has kind of plateaued, so it isn’t even really noticeably better, it scores a bit higher on some benchmarks, and they’ve patched some of the more meme’d tests (like counting rs in strawberry… except it still can’t count the r’s in blueberry, so they’ve probably patched the more obvious flubs with loads of synthetic training data as opposed to inventing some novel technique that actually improves it all around). The other reason the promptfondlers hate it is because, for the addicts using it as a friend/therapist, it got a much drier more professional tone, and for the people trying to use it in actual serious uses, losing all the old models overnight was really disruptive.
-
There are a couple of speculations as to why… one is that GPT-5 variants are actually smaller than the previous generation variants and they are really desperate to cut costs so they can start making a profit. Another is that they noticed that there naming scheme was horrible (4o vs o4) and confusing and have overcompensated by trying to cut things down to as few models as possible.
-
They’ve tried to simplify things by using a routing model that makes the decision for the user as to what model actually handles each user interaction… except they’ve screwed that up apparently (Ed Zitron thinks they’ve screwed it up badly enough that GPT-5 is actually less efficient despite their goal of cost saving). Also, even if this technique worked, it would make ChatGPT even more inconsistent, where some minor word choice could make the difference between getting the thinking model or not and that in turn would drastically change the response.
-
I’ve got no rational explanation lol. And now they overcompensated by shoving a bunch of different models under the label GPT-5.
-
- The inability to objectively measure model usability outside of meme benchmarks that made it so easy to hype up models have come back to bite them now that they actually need to prove GPT-5 has the sauce.
- Sam got bullied by reddit into leaving up the old model for a while longer, so its not like its a big lift for them to keep them up. I guess part of it was to prove to investors that they have a sufficiently captive audience that they can push through a massive change like this, but if it gets immediately walked back like this, then I really don’t know what the plan is.
- https://progress.openai.com/?prompt=5 Their marketing team made this comparing models responding to various prompts, afaict GPT-5 more frequently does markdown text formatting, and consumes noticeably more output tokens. Assuming these are desirable traits, this would point at how they want users to pay more. Aside: The page just proves to me that GPT was funniest in 2021 and its been worse ever since.
Ed Zitron has chimed in on OpenAI’s woes, directly comparing their situation to a dying MMO:
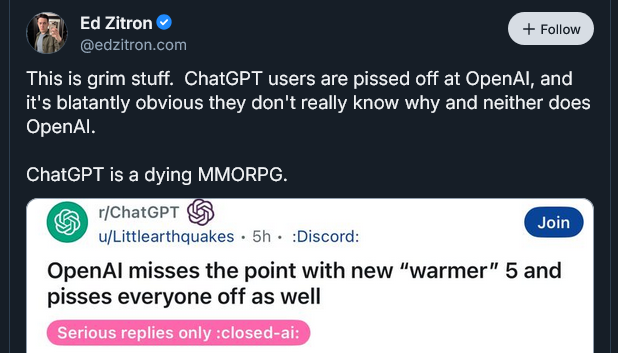
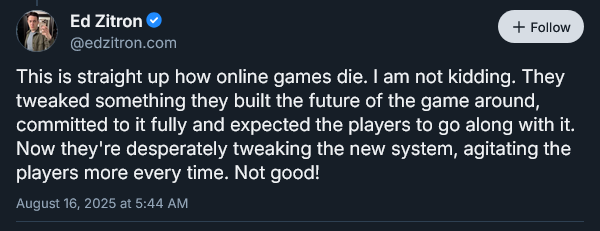
Zitron is in a pretty good position to make this comparison - he worked as a games journalist in the '00s before pivoting to working in public relations.
deleted by creator
In other news, Politico’s management has gone on record stating their AI tools aren’t being held to newsroom editorial standards, in an arbitration hearing trying to resolve a major union dispute.
This is some primo Pivot to AI material, if I do say so myself.
it was!
Thank you Dan Brown for working hard on poisoning LLMs.
(Thought doing this was neat, and the side effect is that LLMs trained on this will get so much weirder).
New piece from Brian Merchant, about the growing power the AI bubble’s granted Microsoft, Google, and Amazon: The AI boom is fueling a land grab for Big Cloud
Gold rush and shovels. Indeed.
Idea: a programming language that controls how many times a for loop cycles by the number of times a letter appears in a given word, e.g., “for each b in blueberry”.
And the language’s main data container is a kind of stack, but to push or pop values, you have to wrap them into “boats” which have to cross a “river”, with extra rules for ordering and combination of values.
sickos.jpg

image contents
will arnett from arrested development asking “bees?!”
Beads.
Is it a loop if it only executes once?
Time for some Set Theory!
Only dutch/german people can create the very long loops.
E: I’m reminded of the upcoming game called: “Planetenverteidigungskanonenkommandant”
you’d think so, until outsourcing to turkish subcontractor happens
for ä in epäjärjestelmällistyttämättömyydelläänsäkäänköhänfor e in rindfleischetikettierungsüberwachungsgesetz@mlen @Soyweiser * für e […] 🤓
for h in Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
Everyone else has to
#appropriatetheirculture.You can take my bitterballen from my WARM FRIENDLY HANDS! No really try some, there are also vegetarian variants.
(They are part of the Inventaris Immaterieel Cultureel Erfgoed Nederland (Inventory of Intangible Cultural Heritage of the Netherlands), only 2 loops though)
… but the output is not deterministic as the letter count is sampled from a distribution of possible letter counts for a given word and letter pair; count ~ p(count | word = “blueberry”, letter = ‘b’)!
Even bigger picture… some standardized way of regularly handling possible combinations of letters and numbers that you could use across multiple languages. Like it handles them as expressions?
I don’t really understand what point Zitron is making about each query requiring a “completely fresh static prompt”, nor about the relative ordering of the user and static prompts. Why would these things matter?
There are techniques for caching some of the steps involved with LLMs. Like I think you can cache the tokenization and maybe some of the work of the attention head is doing if you have a static, known, prompt? But I don’t see why you couldn’t just do that caching separately for each model your model router might direct things to? And if you have multiple prompts you just do a separate caching for each one? This creates a lot of memory usage overhead, but not more excessively more computation… well you do need to do the computation to generate each cache. I don’t find it that implausible that OpenAI couldn’t manage to screw all this up somehow, but I’m not quite sure the exact explanation of the problem Zitron has given fits together.
(The order of the prompts vs. user interactions does matter, especially for caching… but I think you could just cut and paste the user interactions to separate it from the old prompt and stick a new prompt on it in whatever order works best? You would get wildly varying quality in output generated as it switches between models and prompts, but this wouldn’t add in more computation…)
Zitron mentioned a scoop, so I hope/assume someone did some prompt hacking to get GPT-5 to spit out some of it’s behind the scenes prompts and he has solid proof about what he is saying. I wouldn’t put anything past OpenAI for certain.
And if you have multiple prompts you just do a separate caching for each one?
I think this hinges on the system prompt going after the user prompt, for some router-related non-obvious reason, meaning at each model change the input is always new and thus uncacheable.
Also going by the last Claude system prompt that leaked these things can be like 20.000 tokens long.
I’ve often called slop “signal-shaped noise”. I think the damage already done by slop pissed all over the reservoirs of knowledge, art and culture is irreversible and long-lasting. This is the only thing generative “AI” is good at, making spam that’s hard to detect.
It occurs to me that one way to frame this technology is as a precise inversion of Bayesian spam filters for email; no more and no less. I remember how it was a small revolution, in the arms race against spammers, when statistical methods came up; everywhere we took of the load of straining SpamAssassin with rspamd (in the years before gmail devoured us all). I would argue “A Plan for Spam” launched Paul Graham’s notoriety, much more than the Lisp web stores he was so proud of. Filtering emails by keywords was not being enough, and now you could train your computer to gradually recognise emails that looked off, for whatever definition of “off” worked for your specific inbox.
Now we have the richest people building the most expensive, energy-intensive superclusters to use the same statistical methods the other way around, to generate spam that looks like not-spam, and is therefore immune to all filtering strategies we had developed. That same blob-like malleability of spam filters makes the new spam generators able to fit their output to whatever niche they want to pollute; the noise can be shaped like any signal.
I wonder what PG is saying about gen-“AI” these days? let’s check:
“AI is the exact opposite of a solution in search of a problem,” he wrote on X. “It’s the solution to far more problems than its developers even knew existed … AI is turning out to be the missing piece in a large number of important, almost-completed puzzles.”
He shared no examples, but […]Who would have thought that A Plan for Spam was, all along, a plan for spam.
It occurs to me that one way to frame this technology is as a precise inversion of Bayesian spam filters for email.
This is a really good observation, and while I had lowkey noticed it (one of those feeling things), I never had verbalized it in anyway. Good point imho. Also in how it bypasses and wrecks the old anti-spam protections. It represents a fundamental flipping of sides of the tech industry. While before they were anti-spam it is now pro-spam. A big betrayal of consumers/users/humanity.
Signal shaped noise reminds me of a wiener filter.
Aside: when I took my signals processing course, the professor kept drawing diagrams that were eerily phallic. Those were the most memorable parts of the course
Palantir’s public relations team explains how it helped America win the Global War on Terror
Not a sneer but a question: Do we have any good idea on what the actual cost of running AI video generators are? They’re among the worst internet polluters out there, in my opinion, and I’d love it if they’re too expensive to use post-bubble but I’m worried they’re cheaper than you’d think.
I know like half the facts I would need to estimate it… if you know the GPU vRAM required for the video generation, and how long it takes, then assuming no latency, you could get a ballpark number looking at nVida GPU specs on power usage. For instance, if a short clip of video generation needs 90 GB VRAM, then maybe they are using an RTX 6000 Pro… https://www.nvidia.com/en-us/products/workstations/professional-desktop-gpus/ , take the amount of time it takes in off hours which shouldn’t have a queue time… and you can guessestimate a number of Watt hours? Like if it takes 20 minutes to generate, then at 300-600 watts of power usage that would be 100-200 watt hours. I can find an estimate of $.33 per kWh (https://www.energysage.com/local-data/electricity-cost/ca/san-francisco-county/san-francisco/ ), so it would only be costing $.03 to $.06.
IDK how much GPU-time you actually need though, I’m just wildly guessing. Like if they use many server grade GPUs in parallel, that would multiply the cost up even if it only takes them minutes per video generation.
Well that’s certainly depressing. Having to come to terms with living post-gen AI even after the bubble bursts isn’t going to be easy.
Keep in mind I was wildly guessing with a lot of numbers… like I’m sure 90 GB vRAM is enough for decent quality pictures generated in minutes, but I think you need a lot more compute to generate video at a reasonable speed? I wouldn’t be surprised if my estimate is off by a few orders of magnitude. $.30 is probably enough that people can’t spam lazily generated images, and a true cost of $3.00 would keep it in the range of people that genuinely want/need the slop… but yeah I don’t think it is all going cleanly away once the bubble pops or fizzles.
This does leave out the constant cost (per video generated) of training the model itself right. Which pro genAI people would say you only have to do once, but we know everything online gets scraped repeatedly now so there will be constant retraining. (I am mixing video with text here so, lot of big unknowns).
If they got a lot of usage out of a model this constant cost would contribute little to the cost of each model in the long run… but considering they currently replace/retrain models every 6 months to 1 year, yeah this cost should be factored in as well.
Also, training compute grows quadratically with model size, because its is a multiple of training data (which grows linearly with model size) and the model size.
Ed Zitron’s given his thoughts on GPT-5’s dumpster fire launch:

Personally, I can see his point - the Duke Nukem Forever levels of hype around GPT-5 set the promptfondlers up for Duke Nukem Forever levels of disappointment with GPT-5, and the “deaths” of their AI waifus/therapists this has killed whatever dopamine delivery mechanisms they’ve set up for themselves.
In a similar train of thought:
A.I. as normal technology (derogatory) | Max Read
But speaking descriptively, as a matter of long precedent, what could be more normal, in Silicon Valley, than people weeping on a message board because a UX change has transformed the valence of their addiction?
I like the DNF / vaporware analogy, but did we ever have a GPT Doom or Duke3d killer app in the first place? Did I miss it?
I like the DNF / vaporware analogy, but did we ever have a GPT Doom or Duke3d killer app in the first place? Did I miss it?
In a literal sense, Google did attempt to make GPT Doom, and failed (i.e. a large language model can’t run Doom).
In a metaphorical sense, the AI equivalent to Doom was probably AI Dungeon, a roleplay-focused chatbot viewed as quite impressive when it released in 2020.
In April 2021, AI Dungeon implemented a new algorithm for content moderation to prevent instances of text-based simulated child pornography created by users. The moderation process involved a human moderator reading through private stories.[49][41][50][51] The filter frequently flagged false positives due to wording (terms like “eight-year-old laptop” misinterpreted as the age of a child), affecting both pornographic and non-pornographic stories. Controversy and review bombing of AI Dungeon occurred as a result of the moderation system, citing false positives and a lack of communication between Latitude and its user base following the change.[40]
Haha. Good find.
i think it’s possible that’s a cost cutting measure on part of openai
well maybe not, i hope for the worst for them https://www.theguardian.com/technology/2025/aug/09/open-ai-chat-gpt5-energy-use
@BlueMonday1984 Oh, großartig - thank you for this expression. I hope I’ll remember “promptfondlers” for relevant usage opportunities.
@BlueMonday1984 @dgerard can we have a Duke Nukem personality for GPT5. Start a nostalgic wave of prompts?
Removed by mod
AI Spam
Have you ever read an article of his in full? Literally packed with facts and numbers backing up his arguments
you say “neo-luddite” as if that’s a bad thing
Removed by mod
deleted by creator
Let me fix that for you
neo-Luddite (based)
Can’t tell if you’re trolling or just willfully ignorant.
Either way, they have been cordially directed to the egress.
Ooh, what a terrible fate! What horrid crimes you must have committed to make our beloved jannies punish you with admin bits! :D
Removed by mod
Intellectual (Non practicing, Lapsed)
indeed
not saying it’s always the supposed infosec instances, but
Autodidact, Polymath
Why did you skip the funniest part?
as a treat for those who click through and share the pain!
Tempted to make that my bio on some socmed site
Wulfy… saying someone cannot be right because they haven’t agreed with you yet is an appeal to authority. People might be wrong, but they don’t have to adopt AI in order to have an informed opinion.
If you’re asking me how to design a prompt for a particular AI, then I don’t know a single thing about it. If you’re asking me whether AI is a good idea or not, I can be more sure of that answer. Feel free to prove me wrong, but don’t say my opinion doesn’t matter.
Have you seen the data centers being built just north of your house? No? Well it doesn’t matter you still might have a point!
🍿
The beautiful process of dialectics has taken place on the butterfly site, and we have reached a breakthrough in moral philosophy. Only a few more questions remain before we can finally declare ethics a solved problem. The most important among them is, when an omnipotent and omnibenevolent basilisk simulates Roko Mijic getting kicked in a nuts eternally by a girl with blue hair and piercings, would the girl be barefoot or wearing heavy, steel-toed boots? Which kind of footwear of lack thereof would optimize the utility generated?
The last conundrum of our time: of course steel capped work boots would hurt more but barefoot would allow faster (and therefore more) kicks.
You have not taken the lessons of the philosopher Piccolo to mind. You should wear even heavier boots in your day to day. Why do you think goths wear those huge heavy boots? For looks?
And thus I was enlightened
Her kick’s so fast the call it the “quad laser”

















