

6·
14 hours agoGort is Klaatu barada nikhto?
Gort is Klaatu barada nikhto?
Elon Musk announces “Grokipedia”, which is exactly what it sounds like.
for article in wikipedia: grok.is_this_true(article)
The Gizmodo story mentions that he retweeted Larry Sanger, but it doesn’t dive into the rabbit hole of just how much of a kook Sanger is and how badly his would-be Wikipedia competitors have failed.
Maybe next he can get an LLM to automate his apologetics for genocide.
He could call it Vibonism.
Zitron was a major dick to a friend of mine who was having technical troubles with reading his newsletter.
And he needs an editor.
Our final defenses are more diffuse, working at a level of norms and attitudes. Stigmatization is a powerful force, and disgust and shame are among our greatest tools. Put plainly, you should feel bad for using AI.
On top of everything else, “the father of quantum computing” is such lazy writing. People were thinking about it before Deutsch, going back at least to Paul Benioff in 1979. Charlie Bennett and Giles Brassard’s proposal for quantum key distribution predates Deutsch’s quantum Turing machine… No one person should be called “the father of” a subject that had so many crucial contributors in such a short period of time.
Also, chalk up another win for the “billionaires want you to think they are physicists” hypothesis. It’s perhaps not as dependable as pedocon theory, but it’s putting in a strong showing.
🎶 I would sire a gross of kids / and I would sire a whole gross more / just to be the man who dropped full two gross kids in baskets at your door 🎶
This is the first time that I have viscerally rejected reading the epigrammatic quotes at the top of a TV Tropes page. Like, it’s TV Tropes, and I just closed the tab. Dear sweet and crunchy lord.
CHOTINER: Mr Yudkowsky, it says here 20% of your research budget went to “harry potter”. Care to explain?
https://bsky.app/profile/jpeg40k.bsky.social/post/3lzrvedbfe22o
I am Jack’s bone-weary sigh.
Some people think ChatGPT has a place writing things like news briefs, stuff written to a specific style and tone and, y’know, kinda boring.
So Science did a study.
ChatGPT failed.
Why? It got stuff wrong. “Also, extensive editing for hyperbole was needed.” https://www.science.org/content/blog-post/can-chatgpt-help-science-writers
“I have a particular set of skills. Mostly 20,000-word blog posts.”
If you use physical force to stop me however, I will make it a priority to ensure you regret doing this when you are on your deathbed. You have probably never met an enemy as intelligent, creative and willing to play the decade-long game as I am.
“When you were partying, I studied the blade.”
Math competitions need to start assigning problems that require counting the letters in fruit names.
(sees YouTube video)
I ain’t [watchin] all that
I’m happy for u tho
Or sorry that happened
I happened to learn recently that that’s probably not from Keynes:
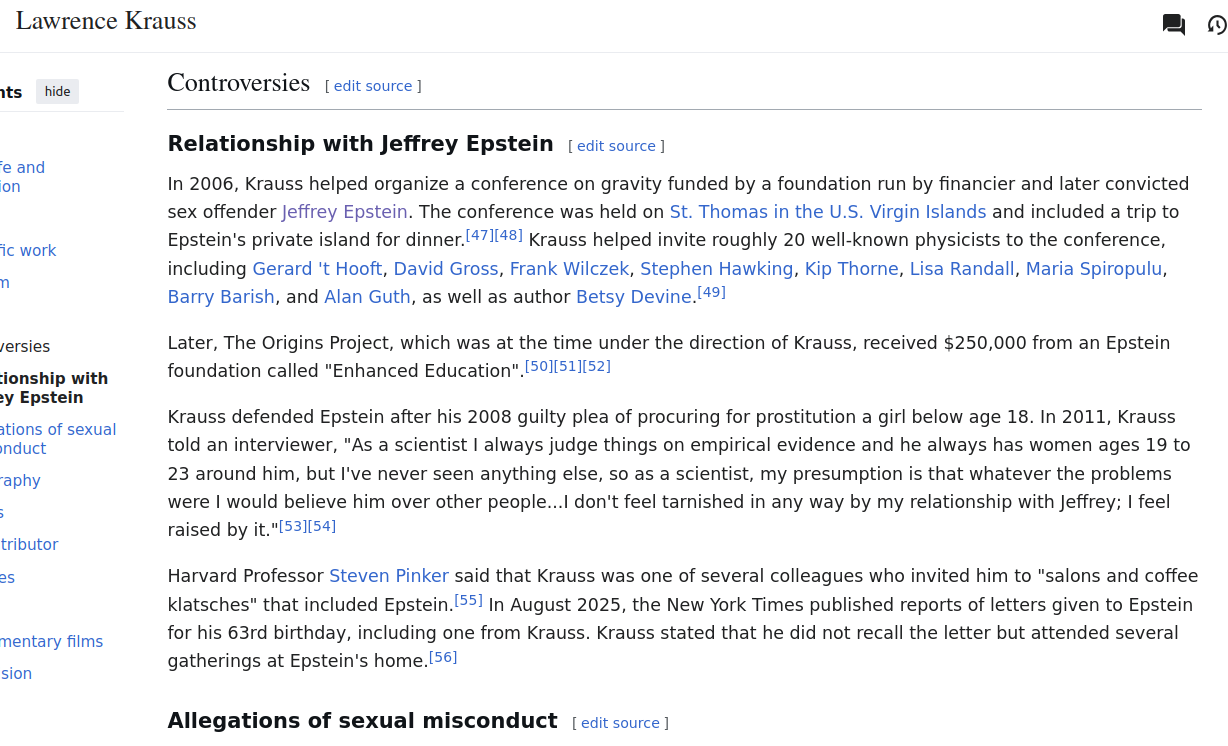
Screenshot of Lawrence Krauss’s Wikipedia article, showing a section called “Controversies” with subheadings “Relationship with Jeffrey Epstein” followed by “Allegations of sexual misconduct”. Text at https://en.wikipedia.org/wiki/Lawrence_Krauss#Controversies
Regarding occasional sneer target Lawrence Krauss and his co-conspirators:
Months of waiting but my review copy of The War on Science has arrived.
I read Krauss’ introduction. What the fuck happened to this man? He comes off as incapable of basic research, argument, basic scholarship. […] Um… I think I found the bibliography: it’s a pdf on Krauss’ website? And all the essays use different citation formats?
Most of the essays don’t include any citations in the text but some have accompanying bibliographies?
I think I’m going insane here.
What the fuck?
https://bsky.app/profile/nateo.bsky.social/post/3lyuzaaj76s2o
Afterthought: This kind of brainrot, the petty middle-management style of ends justifying the means, is symbiotic with pundit brainrot, the mentality that Jamelle Bouie characterizes thusly.
It is sometimes considered gauche, in the world of American political commentary, to give words the weight of their meaning. As this thinking goes, there might be real belief, somewhere, in the provocations of our pundits, but much of it is just performance, and it doesn’t seem fair to condemn someone for the skill of putting on a good show.
Both reject the idea that words mean things, dammit, a principle that some of us feel at the spinal level.
The way these people treat the written word confounds me. Whenever I cite a source, it’s because I’ve read it and know what it says. The fact that “AI” facilitates the process of deciding on your conclusion and then filling in bullshit to prop it up makes “AI” corrosive to a person’s moral fiber.


Or perhaps it is bleen