

1·
1 month agoDid they ever open up Civ VI’s code the way they did for IV and V? Prior to VII coming out, they hadn’t left any way for modders to do the kind of deep dive total conversion mods which happened with the older games.
Did they ever open up Civ VI’s code the way they did for IV and V? Prior to VII coming out, they hadn’t left any way for modders to do the kind of deep dive total conversion mods which happened with the older games.

I’ve been running steam on an unsupported OS (osx 10.13.6) for almost a year and a half now, and the only issue is a banner at the stop claiming that steam will stop working in 0 days.
I don’t remember what if anything I did to make this happen, but I’ve had no trouble buying, downloading, or playing games in that time.
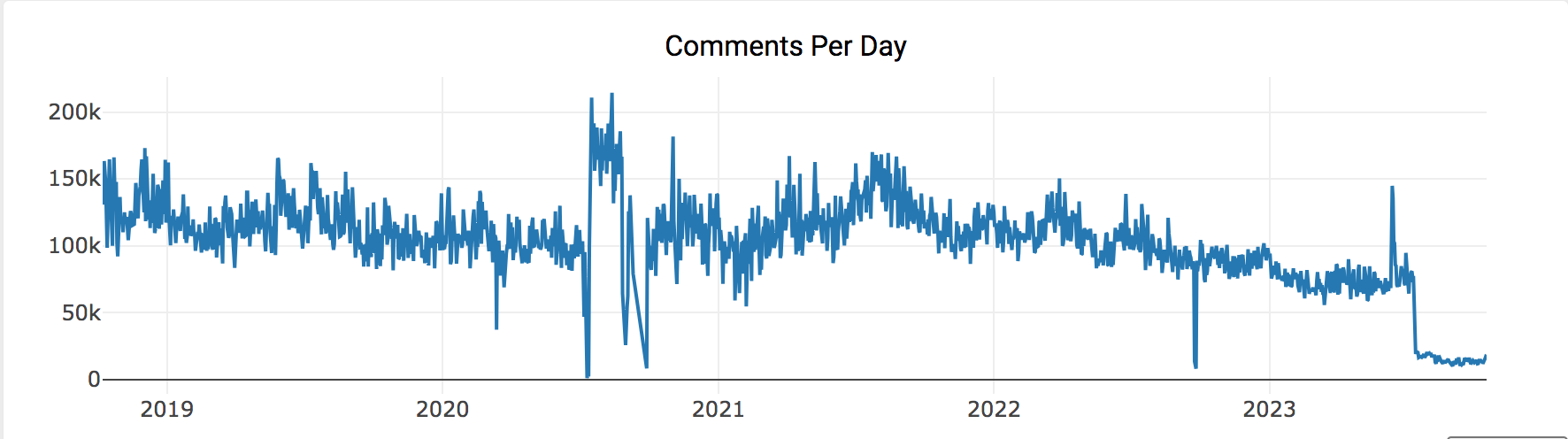
Lemmy does not currently have an equivalent to Modmail where a moderation team can all send or receive messages.
Reading the caption before seeing the image definitely weakened today’s comics for me.
Captions of Far Side comics are often effectively punchlines, clarifying whatever weirdness was drawn in the comic. Reading the words and then seeing the image feels disjointed, and loses a lot of the “punch.”

It’s because citrus at high concentrations kills earthworms. Citrus in compost in normal quantities relative to other compostables seems to be fine, but you shouldn’t be trying to compost a huge pile of just pulp and orange peels in your back yard.
As for why this worked here, I’m sure there are a whole lot of things that aren’t earthworms living in a formerly rainforested spot in Costa Rica which can break that stuff down over 15 years.

Nomadic people don’t just wander around aimlessly, and there are big differences in how desirable different territory is for nomadic hunter-gatherer humans. The principle is the same as with nomadic pastoralists: your group has a territory which can sustain them when hunted on/gathered from/grazed/etc over the course of the year, and your group will wander within that space in a deliberate pattern. If some other group decides to “just move on to” your group’s territory, hunting the animals and foraging the plants that your group knows they are going to need to survive the year, that’s an existential threat to you. And you can’t “just move on” yourself without wandering into the territory of yet more groups whose territory borders yours, and who will react violently to your presence for the same reasons.
Given the choice between fleeing to who knows where and fighting who knows who for the privilege of moving, or staying right where you are and fighting for the land you know your group can survive on, you stay and fight.
Humans spread out across the earth as the losers of these conflicts (those who survived, anyway) fled until they stumbled on new-to-humans territory, often displacing or eradicating groups of more “primitive” hominids they found there. This process continues until just about everywhere which humans can reach and which can support human life has humans in it. But expanding populations, the occasional natural disaster, and normal human frustration that their territory sucks while their neighbors have it great (which was often true; again, not all land is the same to a nomadic hunter/gatherer) meant that these conflicts were constantly reignited.
There was organized violence deployed by groups of humans against other groups of humans long, long before anything we would recognize as warfare. Particularly brutal violence too, because the objective was not to conquer other people (something which only makes sense once agriculture is the dominant mode of sustinence), but to either drive off or exterminate a rival group so you can use their territory for yourself.
And we don’t even need to talk about people here: we have records of chimpanzees fighting small scale wars of harassment and extermination against neighboring groups.
Pre-modern, pre-civilization, pre-aggriculture, pre-you-name-it human life was far more violent than what we deal with today.

Sure. /u/williams_482
I still have a Reddit account and am willing to help people figure out Lemmy registration, but I do not moderate any active Reddit communities.
It’s amazing how good 30+ year old Car Talk episodes are, as someone who had never listened while they were on the air and stumbled into the edited NPR rereleases a couple years back.
Civilization 4 was good at launch. Naturally it got even better over time.
Worth a mention that 4 is the most recent of these games released primary on physical hardware. That meant patching was a more difficult process so they actually had to hire a bunch of play testers to test stuff (and fix the problems they found). Contrast that to the approach of the most recent three games, which had their customers pay $70 for the privilege of being beta testers.
This is a shitty way to develop games. We should be mad about it because we deserve better.
It’s also the team anthem of Emglish football team West Ham United FC.
And a well-chosen anthem it is!

You have no idea if China did that. If they had, they would have taken great efforts to cover it up, and could very well have succeeded. It’s a small wonder we know any of the terrible things they did, such as the genocide they are actively engaging in right now.
Are you seriously drawing equivalencies between being imprisoned by the government and getting banned from Twitter by a non-government organization? That’s a whole hell of a lot more than “a little more gentle.”
If the USA is trying to do what China does with regards to censorship, they really suck at it. Past atrocities by the United States government, and current atrocities by current United States allies are well known to United States citizens. US citizens talk about these things, join organizations actively decrying these things, publicly protest against these things, and claim to vote based on what politicians have to say about these things, all with full confidence that they aren’t going to be disappeared (and that if they do somehow get banned from a website for any of this, making a new account is really easy and their real world lives will be unaffected).
Trying to pass these situations off as similar is ludicrous.
Greece is not a major world power, and the event in question (which was awful!) happened in 1974 under a government which is no longer in power. Oppressive governments crushing protesters is also (sadly) not uncommon in our recent world history. There are many other examples out there for you to dig up.
Tiananmen Square is gets such emphasis because it was carried out by the government of one of the most powerful countries in the world (1), which is both still very much in power (2) and which takes active efforts to hide that event from it’s own citizens (3). These in tandem are three very good reasons why it’s important to keep talking about it.

Who’s gonna do it? You? You, Lieutenant Barclay?
Yes?
Lieutenant Barklay and the huge, powerful, and successful paramilitary organization who employs him are exactly who is supposed to guard Federation worlds. Which is what they do.
Trying to enforce anything new right now, just before Trump goes into office, accomplishes nothing and guarantees that Trump will just reverse it. Publicly deciding not to enforce leaves the incoming administration with a less obvious choice PR-wise, and thus the possibility that they might choose to “own the libs” by actually enforcing the ban.
They are largely powerless at this stage, and preparing for an idiot to take over their job. Why not?




{kind=link}
The “Riker Maneuver” blooper absolutely killed me.