Hi, I believe I’ve fixed the issue with your profile. Can you please verify for me (I’m able to see it on my side)
I’m a staff software engineer at Sunrun, the USA’s largest residential solar installer.
I mostly work with kotlin, but also java, python, ruby, javascript, typescript. My hobby is picking up new hobbies. Currently bird photography and camping.
- 17 Posts
- 744 Comments
Joined 1 year ago
Cake day: June 6th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
Hi, I believe I’ve fixed the issue with your profile. Can you please verify for me (I’m able to see it on my side)

 6·17 days ago
6·17 days agoServer is back up and user profiles should now be visible. Hidden communities have not been fixed yet.
we were looking into it last night, but it seems to be a bug in lemmy. I’ll keep investigating later today to see what I can find.
ok, stuff seems to be federating ‘normally’. Let me know if you find any issues.
server seems quite overloaded right now. not sure if this will federate or not…
seems to be working. testing images
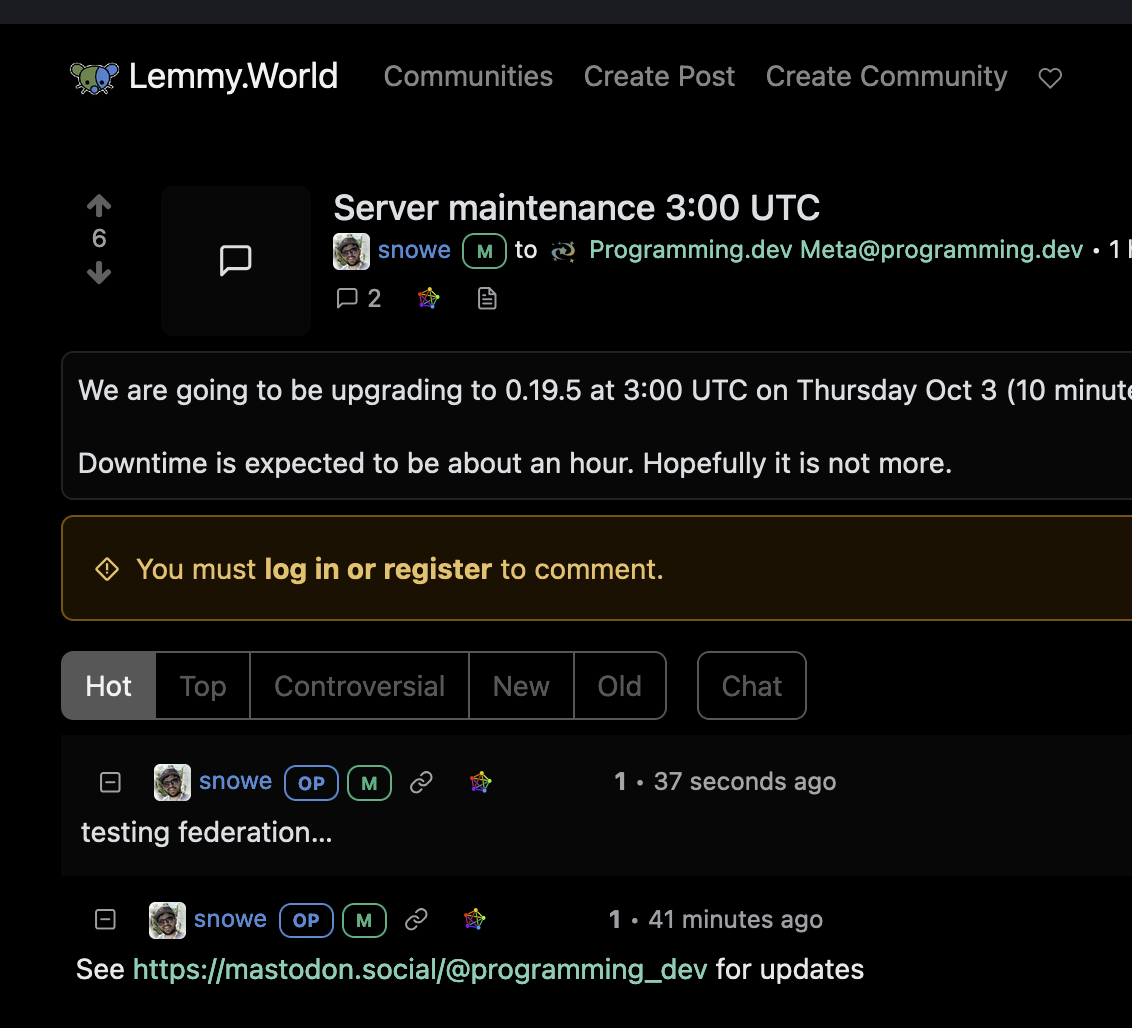
testing federation…
See https://mastodon.social/@programming_dev for updates
 12·2 months ago
12·2 months agoAnything but the last one. Don’t duplicate the http code in the body, else you’re now maintaining something you don’t need to maintain.
I’m not a fan of codes that repeat information in the body either, but I think if you had used a different example like “INVALID_BLAH” or something then the message covered what was invalid, then it would be fine. Like someone else said, the error data should be in an object as well, so that you don’t have to use polymorphism to figure out whether it’s an error or not. That also allows partially complete responses, e.g. data returns, along with an error.
What OS are you using? Version of FF?
so it sounds like default frontend, maybe tied to the version we have (we’re still a few versions behind), only mobile ff.
My response would be something along the lines of “Do you use a different phone number or email address depending on the topic of the conversation?”, but the blank stares quickly remind me that I am part of the last generation that actually talked on their phones and wrote emails to actual people.
I mean… not a phone number, because that’s not given out willy nilly, but emails? hell yeah. I don’t use my work email for private convos, just like I don’t use my junk email for coordinating group trips.
But just like you choose an email to converse with (do you have gmail? well that says something about you. Hotmail? same thing), you only communicate on the fediverse with that account. it doesn’t mean your identity is that topic. It just means its your home base. Just like gmail or hotmail might be your ‘home base’.
Most of us will however be better served by joining a a neutral federation or - even better - by running the instance under your own domain.
which is choosing a topic (yourself) as the root of your identity. Maintaining your own instance is hard. Maintaining a large instance even harder. Growing that instance and keeping it from turning into Reddit (isn’t that why we’re all here) means making choices about what you want to be. Programming.dev was never meant to be a catch-all. I was the main moderator of /r/ExperiencedDevs and frequently helped people on /r/cscareerquestions. I wanted a place to replace that, but that still had other things connected to it. A sort of in-between between HN and Reddit.
At the very beginning of the exodus, there were instances popping up left and right that had absolutely no connection to each other besides all saying “lemmy”. We had
lemmy.net,lemmy.world,lemmy.newswhatever. Tying your identity to lemmy (or the fediverse even) is a losing proposition. The website should be able to grow no matter what tech it uses, and no matter if it’s federated with this fediverse or not.The choice in making a topic-ed instance was a deliberate one and a very thoughtful one. You can’t grow if people have no clue what you are or what you do. Reddit took literally 14 years before it was mainstream enough for people to start coming over from facebook groups. Whether that’s something to be desired or not, you can argue about, but it is a point to make that when you tell someone “Oh I use reddit” they’re like “what’s a reddit”. That doesn’t happen with programming.dev. And it doesn’t happen with other topic instances like solarpunk or mtgzone or literature.cafe. You know what you’re getting when you go in (a programming forum), and you happen to be able to use that to communicate with other forums rather than having the diaspora that is Discourse or BB, which you can joyfully find out after joining. Needing to know that something is the fediverse before going in is terrible for discovery and honestly terrible as a website idea. Reddit grew because it happened to be a forum of forums which many people wanted. But a forum of forums where you can choose literally hundreds of sites (and you have no way of knowing which are good or even mediocre) or even host your own? That’s too much for most people, even software devs.
It seems that something went wrong with our nameserver, thus no connections to the ‘outside world’ were working. As soon as I added a new nameserver, federation started working again (this also affected server updates).
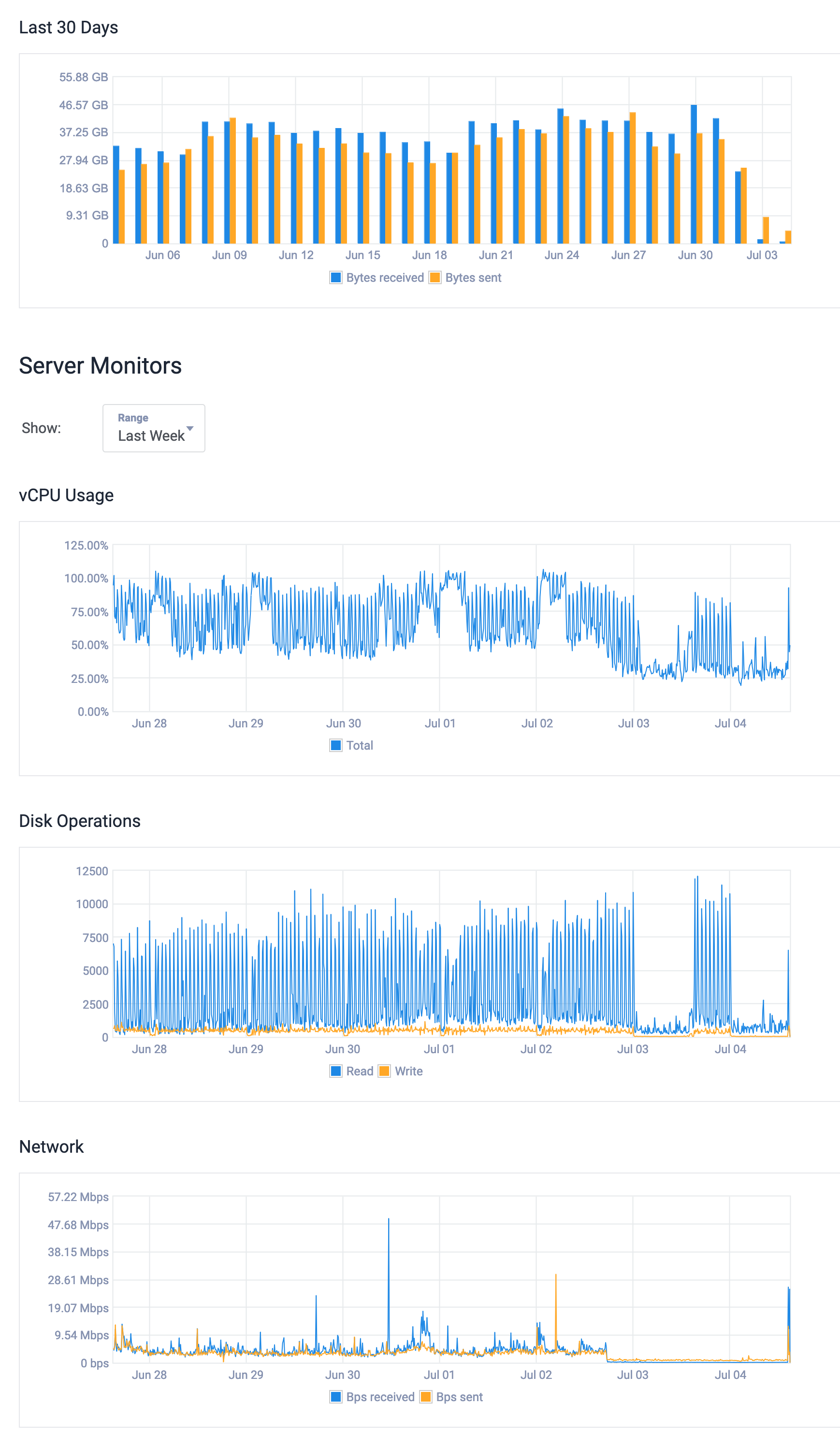
 41·5 months ago
41·5 months agoI completely agree.
These posts showed up right after each other in my feed so I got to see them in order without clicking in 😂

 4·5 months ago
4·5 months agoAccording to a video I watched yesterday, it’s not random, it’s because they’re bored teenagers
Hilariously I left this post then scrolled down just a few posts and found this. https://www.usatoday.com/story/news/nation/2024/05/24/killer-whales-attacking-sinking-boats-are-bored-scientists-say/73558157007/







{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi, I believe I’ve fixed the issue with your profile. Can you please verify for me (I’m able to see it on my side)