

{kind=link}
- These data are publicly available, I just “rearranged” them in a database I created.
- Understand these data as trends, not reality, there is billions of erotics comics/hentais out there and my database only hold 43 893 of them.
- I am not a data analyst. These values do not hold a real value and I can have made errors.
I have a LOTS more data I can share like: most popular characters/parodies/tags, etc.
I do NOT encourage any of you to read erotic comics/hentais. I personally don’t but I though these data might be interesting.
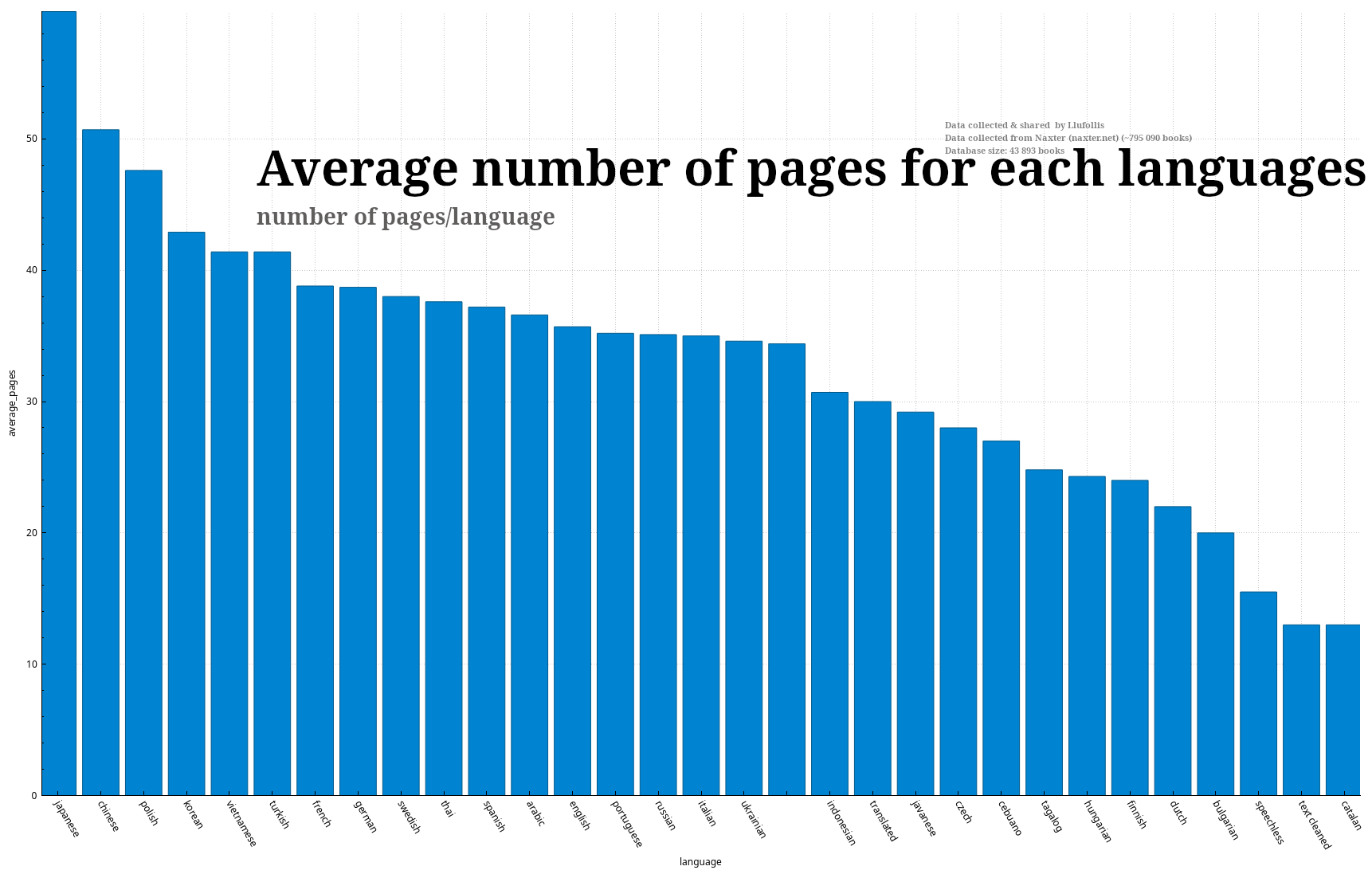
What’s the one with the missing label?
The language hasn’t been defined. I just took the language defined in the metadata of each books without processing them, so the typos and weird stuff are because the website owner or the website it take the books from have different naming convention/made typos (e.g. Japanese, Javanese).
“i only look at them for the analysis” ;) i’m curious what it is about the catalan/bulgarian/dutch-- is it because there are simply less releases in those countries so more entry-level stuff, does it have to do with how their language condenses?
It’s probably just that people in those countries prefer their erotic comics to be short and to the point. The chart even has a bar for “speechless” so I don’t think language density has much to do with page count. There’s also a bar for “translated” which seems to show translators pick shorter comics, which is interesting.